

テキスト、テキスト、テキスト!
オフィスの情報の多くは文書、すなわちテキスト情報である。このデータをいかにうまく処理するかが、効率的なオフィスシステムを構築するときのキーポイントになる。
- 前回の復習
- なぜテキスト形式にこだわるのか
- 情報の寿命
- ハイパーカードのテキスト処理
- 簡単なデータベースへの応用
- データファイルの作成
- タイトルの抽出
- 内容の表示
- 検索機能を加える
- 電子掲示板との連動
- 掲示板データベースの作成
- テキストデータの応用
前回の復習
前回はハイパーカードがオフィス処理を行うに当たって強力なツールになりうることを示した。その理由として
- 優れたテキスト処理能力
- 自動操作と高度なカスタマイズ
- バンドルされる無料ソフト
の3つを挙げ、第2のポイントの具体例としてドキュメントローンチャと簡易電子掲示板を作成した。今回は、第1のポイント、テキスト処理に的を絞ってオフィスシステムの構築を考えてみることにしたい。
なぜテキスト形式にこだわるのか
前回も述べたように、オフィスで扱う情報の大半は文書、すなわちテキストである。材料となるデータを探してきて、それを説得力のある報告書や企画書にまとめる。日常の仕事にはこういう作業が多いのではないだろうか。
最終的な完成品には見栄えの良さが必要だとしても、データの蓄積や加工の段階では、レイアウトなどの余計な情報を付加しない、純粋なテキストのほうが扱いやすい(*注1 )。例えばデータを特定のファイル形式にすると専用のアプリケーションでしか扱えなくなってしまうが、テキスト形式ならどんなソフトでも直接利用できる。
特定形式で保存された情報は、いわば調理済みのお惣菜のようなものだ。データは加工し組合せることで新しい価値を生み出す。その素材はできるだけ生のままで、調理しやすい形にしておくべきなのである。
情報の寿命
これとは別に、テキストにこだわるもう一つの大きな理由がある。情報の寿命とでもいうようなことだ。
わずか十数年のパーソナルコンピュータの歴史でも、いろいろな機種の栄枯盛衰があった。今のところマッキントッシュとウインドウズの2つが主流となっているが、この先もこれらが広く使われるという保証はない。実際、日本のオフィスに急速に普及した専用ワープロは、今コンピュータに席を譲ろうとしているが、それに際してこれまでの文書資産をどうやって引き継ぐかが問題になっている。専用ワープロは各社が独自のフォーマットにこだわったため、データの互換性に大きな障害を残してしまったのだ。
オフィスの情報は、何十年という単位で活用されるべきものである。これを時の流行りに合わせて特定の機種と心中させるわけにはいかない。この点で、最も汎用性がある情報記録形態が「テキスト」ファイル形式なのである(*注21 )。細かいことは別にして、これならば他のコンピュータ上でも再利用可能だ。
大切なのは機械ではなく情報自身である。財産を汎用性のあるテキスト形式にしておくことは“転ばぬ先の杖”と言ってよい。
ハイパーカードのテキスト処理
ハイパートークではcharacter, word, item, lineなどの識別子でテキストの要素を指定し、put命令で前や後ろに繋ぐというような文字列操作ができる。たとえば
put "Taro loves Hanako" into S1 delete last character of word 2 of S1 put "Does " before S1 put "?" after S1
とすると、S1の中身は"Does Taro love Hanako?"という疑問文に変換されるわけだ。さらにoffset 関数やcontains 演算子を使えば一つの文中に特定の言葉が含まれるかどうかを調べられるし、sort 命令を使えば一定規則により文を並べ替えることもできる。ハイパーカードの内部では数字も文字列として処理されるので、数字と文字が入り交じったデータの処理も簡単である。
豊富な命令をここで全て紹介するわけには行かないが、ハイパートークのテキスト処理は強力で柔軟である。こうした機能を組み合わせることで、素材となる文を自由に加工し、新しい情報として付加価値を与えることが可能になる。
簡単なデータベースへの応用
 ハイパーカードの機能を使って、簡単なテキストデータベースを作ってみよう。ハイパーカードはカード1枚に一つのレコードを納めて、カード型データベースのように使うことが多いが(付録で付いてくる住所録などがそうだ)、ここではテキストファイルにこだわって、データ自身はスタックとは別のファイルに持つことにする。
ハイパーカードの機能を使って、簡単なテキストデータベースを作ってみよう。ハイパーカードはカード1枚に一つのレコードを納めて、カード型データベースのように使うことが多いが(付録で付いてくる住所録などがそうだ)、ここではテキストファイルにこだわって、データ自身はスタックとは別のファイルに持つことにする。
一般に、データの入れ物とデータ自身を独立させておくのは賢明な手法である。こうすることでデータの加工が容易になるだけでなく、将来システムを見直すことがあってもデータは無傷で残すことができるし、そのまま他の機種に持っていくことも可能だからだ。
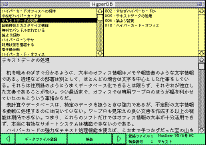
ここで作成するのは、カードの左上では常にタイトルの一覧が表示されていて、必要なタイトルをクリックするとその内容が下部に表示されるという形を取る(図1)。データベースのリスト表示と個別表示を同時に使う感覚だ。
データファイルの作成
まず、素材となるデータを用意する。データの要素はタイトル(1行)と内容の2つのみ。たとえば、この原稿を1つのデータベースとすると、小見出しを「タイトル」、それに続く本文を「内容」と考えることができる。データ中の個々のレコードを区別するために、内容と次のタイトルを半角ハイフン2つ(--)だけの行で区切ることにする(*注3 )。つまり
タイトル1 内容1 ・・・ 内容1の終わり -- タイトル2 内容2 ・・・ 内容2の終わり --
という具合になる。素材は何でも構わない。毎日の営業日誌でも良いし、いろいろなアイデアのメモでも良い。手元に転がっている雑多なデータを、気楽に--で区切ったテキストファイルにしてみよう。
タイトルの抽出
データができたら、ここからタイトルを抽出して見出し一覧を作成する。リスト1 に示したように、ファイルを読み込んで(*注4 )1行ずつデータを検証し、区切り行(--)が現れたら次の行はタイトル、その次の行からは内容とみなして処理していく。ポイントは、区切り行の位置をインデックスとして記録するところである。一覧表でタイトルが選ばれたら、このインデックスを頼りにファイルから内容を読み出す。
ここでインデックスの最初が0になる(on updateDataの5行目)ことに注意。データファイルの先頭には区切り行は置かないが、先頭行の前(つまり0行目)に仮想的に区切り行を設定して、読み出し処理を簡単にしているのである。
内容の表示
タイトル一覧を表示しているフィールドは「ロックテキスト 」をチェックし、マウスのクリックを受け付けるようにしておく。フィールドのスクリプトはリスト2 のように簡単なものだ。クリックされた行を調べ(word 2 ofthe clickLine )、インデックスフィールドからそれに対応する区切り行(--)の位置を取得し、ファイルから内容を読み出して表示する。
検索機能を加える
データベースと名乗るからには検索機能も用意したい。ハイパートーク命令だけでは高速検索は難しいが、いろいろ応用の利くスクリプトなので検討してみよう(リスト3)。
データファイルを読み込んで、検索語句が含まれるかどうかをcontains演算子で順番に調べていく。全文検索をすると同一レコードで複数ヒットする場合があるので、結果リストを作る前にこのチェックをしておかなければならない。
検索結果は、タイトルとそれが一覧中の何番目に当たるかを示す行番号をセットにして返す(図1の右上のフィールド)。スピード優先なら、全文検索を諦め、登録されたタイトルに検索語句があるかどうか調べることで我慢するという手もある。
結果リストフィールドでは、この行番号を頼りにインデックスを調べ、内容を表示するようにした(リスト4 )。基本的には前節の内容表示スクリプトと同じである。
電子掲示板との連動
さて、これだけの機能なら専用データベースソフトを使ったほうが高速なものができるわけで、このままではハイパーカードを使う必然性はあまりない。しかし、これを前回作った電子掲示板と組み合わせるとなかなか面白い使い方ができる。
前回の掲示板は日付をファイル名にすることで表示すべき情報を識別していた。しかしこれでは、指定の日に出張していた人には情報を伝えることができないし、情報をさかのぼって調べることも難しい。そこで、メッセージをテキストデータベースの形で蓄積し、新しい情報が追加されたときに掲示板を自動表示するようにしておけば(図2)、確実にメッセージを伝達でき、古い情報も有効に活用することが可能になるはずだ(図3)。
データベースの側面から見れば、単に情報を蓄積するだけでなく、新規情報を直ちにメンバーに知らせられる点がユニークと言える。受け身のデータベースが、ユーザーへ積極的に情報提供するダイナミックなものに変身するわけだ。
掲示板データベースの作成
この掲示板データベースを作るには、前に述べた区切り行付きテキストファイルの形式で新しいメッセージをファイルの先頭に順次追加していくだけでよい。ファイルを保存したらタイトル抽出を行う。前と違うのは、抽出したタイトル一覧とインデックスを、フィールドでなくファイルに保存するところである。スタックの起動プロセスの中で毎回このファイルをチェックし、トップに来るタイトルがまだ読んだことのないものであれば新規メッセージが送られたものとみなして、スタックのフィールドを更新し、メッセージの内容を表示するという仕掛けだ(リスト5 )。
テキストデータの応用
データベースほど手間をかけなくてもテキストデータを活用する方法はある。
例えば、共有ファイルのフォルダを作っているようなケース。少数のファイルならともかく、100にも及ぶファイルから必要なものを見つけるのは簡単ではない。ここに今回の手法を応用してみよう。
ファイルを保存するとき、それぞれ内容を説明する<文書タイトル>を、先のデータベースの“タイトル一覧フィールド”に登録するようにしておく。“インデックスフィールド”には行番号の代わりにファイル名を登録する。こうすれば、文書タイトルに基づいて簡単に必要なファイルを検索・表示する仕組みができあがるというわけだ。この簡易ファイル登録システムは、ファイル名よりも詳しい説明が付加できるうえに、いちいちワープロソフトを立ち上げなくてもテキストを参照することができる(*注5 )ので、思いのほか便利である。
* * *
ハイパーカードの命令だけでもこれだけの機能を実現できるが、外部命令を使えばもっとスマートに高速にデータを処理することが可能だ。タイトルの一覧をダイアログボックスで表示したり、フォルダ内の全テキストファイルに対して一括全文検索をかけるということもさほど難しくない。こうした外部命令については、また回を改めて紹介していく予定である。
注
*注1
テキスト形式で文書を作成するのには、エディタと呼ばれるソフトを使うのが便利である。これらの多くはフリーソフトとして入手できるのでなお都合がよい。ワープロを使う場合は、保存文書のファイルタイプが「TEXT」のものだと、文字部分は直接ハイパーカードからも参照できるので、いろいろな応用が可能である。
*注2
エクセルのように複数機種で使える有力なファイル形式もあるが、テキストほどの汎用性はないし、これらがこの先何十年も主流であるとは限らない。
*注3
区切りはどのようにしても良いのだが、こうしておくとフリーウェアのEasy Viewでデータを直接リスト表示することができる。繰り返すが、テキストファイルはこのようにいろいろなアプリケーションから縦横に活用できるのである。
*注4
データ読み込みの命令は頻繁に利用するので、リスト1 のようにReadFile()という関数を作ってスタックスクリプトに置いておく。こうしておくと、エラー処理、統計など将来ファイルまわりの命令を追加するときもここを修正するだけで良い。
*注5
ファイルタイプが「TEXT」になるワープロやエディタを使っていないと、ハイパーカード上で内容を閲覧するのは難しくなる。こういう点を見ても、テキスト形式のメリットが理解できるだろう。
リスト
リスト1
on mouseUp
answer file "データファイル" of type TEXT
if it is "" then exit mouseUp
updateData it
end mouseUp
on updateData FileName
set cursor to watch
put ReadFile(FileName) into str -- ファイル読み込み
put "" into titles
put "0" & RETURN into Indexs -- 0行目を仮想的に区切り行扱いする
put "--" into separator
put TRUE into header -- タイトルかどうかを判定
repeat with i=1 to number of lines of str
set cursor to busy
if header is TRUE then
put line i of str & RETURN after titles
put FALSE into header
else if line i of str is separator then
--区切り行なら行番号をインデックスに加え、次の行がタイトルであることを示す
put i & RETURN after Indexs
put TRUE into header
end if
end repeat
put titles into fld "Title"
put Indexs into fld "Index"
put lastHCItem(":", FileName) into line 1 of fld "FileInfo"
put FileName into line 2 of fld "FileInfo"
end updateData
function ReadFile FileName
open file FileName
read from file FileName until EOF
close file FileName
return it
end ReadFile
リスト2
on mouseUp showData (word 2 of the clickLine) -- クリックした行 end mouseUp on showData LineNo put line lineNo to LineNo+1 of fld "Index" into POS -- Indexの対応する行が前のレコードとの区切り、 -- 次のIndexが次のレコードとの区切り行を示している put ReadFile(line 2 of fld "FileInfo") into str put line (line 1 of POS +1) to (line 2 of POS -1) of str into fld "TEXT" -- line (line 1 of POS) to (line 2 of POS) of strとすると区切り行も含まれる show fld "TEXT" end showData
リスト3
on mouseUp
ask "検索語句?" with fld "SearchWord"
if it is "" then exit mouseUp
put it into SearchWord
put ReadFile(line 2 of fld "FileInfo") into str
put "" into res
-- SearchWordを含むかどうか1行ずつ調べる
repeat with i=1 to number of lines of str
set cursor to busy
if line i of str contains SearchWord then
put i & RETURN after res
end if
end repeat
if res is "" then
answer "「" & SearchWord & "」は見つかりませんでした。"
exit mouseUp
end if
-- 同一レコードでヒットしたものをまとめる
put fld "Index" into Indexs
put fld "Title" into titles
put 1 into currentPos
put number of lines of Indexs into n
set numberFormat to "000"
-- SearchWordが含まれる行番号について
repeat with i=1 to number of lines of res
repeat with k=currentPos to n
if line i of res < line k of Indexs then
-- インデックスの行番号が検索結果の行番号より大きければ、この結果は
-- 一つ前のレコードに含まれることになる
if k is currentPos then exit repeat -- 同一レコードのヒットは省略
put k into currentPos
-- タイトルの前に一覧中の何番目に当たるかを示す行番号を付加する
put k-1 && ":" && line k-1 of titles & RETURN after foundSec
exit repeat
end if
end repeat
end repeat
put foundSec into fld "List"
show fld "List"
end mouseUp
リスト4
on mouseUp put word 2 of the clickLine into thisLine -- 検索結果でクリックした行 -- タイトル一覧での行番号をリスト2 のshowDataに送る showData (word 1 of line thisLine of me) end mouseUp
リスト5
on startUp
--
put <message title file> into msgTitle -- 抽出したタイトルを保存するファイル
if there is a file msgTitle then
put ReadFile(msgTitle) into Titles
put "MsgBoard" into cdName
-- タイトルの1行目を前回表示したメッセージのタイトルと比較し、
-- 新しいタイトルが保存されていればカードを更新する
if cd fld "LastMsg" is NOT line 1 of Titles then
go cd cdName
updateData <message file> --リスト1
と同様にしてデータの更新
put line 1 of Titles into cd fld "LastMsg"
showData 1 --リスト2
のshowDataに最初のレコードを読むよう依頼する
end if
end if
--
end startUp
用語
- offset
-
ある文字列S1が別の文字列S2の何文字目に含むまれるか(もしくは含まれないか)調べます。
put "Mac" into S1 put "This magazine is MacUser Japan" into S2 put offset(S1, S2) into pos
とすると、変数posには18という結果が代入されます。S2(の先頭)はS1の18文字目にあることが分かります。
日本語の扱いはHC2.1とHC2.2の間で変更されているので注意が必要です。HC2.1ではoffsetが返す値はバイトポジション(全角1文字が2バイト)であったのに対し、HC2.2ではcharつまり何文字目かという値になっています。
- contains
-
ある文字列S1が別の文字列S2を含むかどうか調べます。
put "This magazine is MacUser Japan" into S1 put "Mac" into S2 if S1 contains S2 then ...
のように使います。よく似ていますが、S1とS2の関係が逆となるものにis in演算子があります。上の例で言えば3行目が
if S2 is in S1 then ...
という形になります。いずれも結果はTRUE/FALSEで返されます。
- sort
-
表計算のワークシートから書き出したような行単位のデータを扱うとき、この命令で並べ替えを行う。例えば、データstrが氏名,身長,体重の順でitemとして区切られているとき、
sort str descending numeric by item 2 of each
とすると、データを身長の高い順に(降順に)並べ替えることができる。
- ロックテキスト
-
フィールドの属性の一つで、これがFALSEならばフィールドのテキストを編集できる。逆にTRUEになっていると、そのフィールドは編集できない代わりにマウスのクリックを受け付けるようになる。フィールドスクリプトにmouseUpなどのハンドラを処理させるにはテキストをロックしておく必要がある。
- the clickLine
-
ロックテキストされたフィールドをクリックしたとき、この関数を使うと何行目をクリックしたかを調べることができる。例えば、フィールドの3行目をクリックすると、the clickLineの結果は
line 3 of bkgnd field 1
のようになる。従って、行番号を得たいときは
word 2 of the clickLine
とすればよい。
(MacUser Japan, July 1995)