

捜し物は何ですか?
机だってディスクだって、きちんと整理したいのは山々だが、なかなか思うように行かないのが世の常だ。ハイパーカードはそんなあなたにも救いの手を差し延べる。
- とかく整理は難しい
- ファイルはどのように保存するべきか
- 31文字で分かるか
- 必要なファイルを見つけだす
- 条件を追加して調べる(AND検索とOR検索)
- ファイルから段落を抽出する
- 検索辞書(シソーラス)を用意して効率的にファイルを探す
とかく整理は難しい
これまで、テキストで情報を保存することの利点を説き、具体的な活用例としてテキスト形式の簡易データベースを紹介してきた。これはうまい使い方をすると強力なもので、いろいろな応用や加工が簡単にできるし、先月号で見たようなハイパーリンクすら可能になる。悪くない。
しかし、情報の全てがこんなに整然と管理できるわけではないだろう。取りあえず書類を提出するのが先で、あとできちんと整理しようと思いつつ時間が経って、ファイルの山の中に埋もれてしまったという経験は誰でもあるはずだ。
ハイパーカードオフィスは、理想だけを唱える非現実的なものではない。オフィスの現状をきちんと把握し、ユーザーの使いやすさを考えた上で全体としての情報パワーを向上させる方法を見つけることが大切である。管理に都合よく作成されたものだけでなく、気楽に作ったデータも活用できる手段を提供してこそ、ユーザー本位のオフィスシステムというものだ。
今回はファイルの管理方法と、ハイパーカードの役割について考察することにする。
ファイルはどのように保存するべきか
改めて言うまでもないようなことだが、フォルダはプロジェクト(内容)ごとに作り、その中に関連するファイルをまとめて保存するのが利用しやすい(画面1)。作成アプリケーション毎ではなく、仕事の内容で文書を管理するのが基本であるはずだ。
ところが、マッキントッシュにはプロジェクト単位でのファイル整理という概念が存在しないのか、こういう使い分けが自然に行えない。例えば、書類をダブルクリックして開いたのに、そこで新規書類を作成して保存しようとすると、ダイアログではもとの書類とは無関係に「アプリケーションのあるフォルダ」が開かれてしまう(*注1)。意識的にフォルダを選んで保存しないと、迷子のファイルが生まれることになるのだ。
ファイルをプロジェクトごとにまとめるという整理法は、慣れてしまえば当たり前のこととはいえ、意外にどんな入門書にも書かれていない。デスクトップにファイルが無造作に散らばっていたり、アプリケーションのフォルダにごっそり文書が保存されているのは、初心者のコンピュータに限らないようだ。文書管理の第一歩がファイリングということは、紙の書類の場合は常識である。コンピュータでもファイル管理のルールが是非とも必要だ。このルールが徹底されないと、ファイルがあちこちに分散し、必要な情報を探すのに手間取ることになる。
31文字で分かるか
ルールが守られフォルダの使い分けはうまくできたとして、ではどのような名前を付けて保存するか。問題は情報を共有しようというときである。「12/18○○新聞社長取材」というファイル名では、担当者には意味するところは明らかでも、別のメンバーにとっては、規制緩和に関する取材なのか、趣味のゴルフの話なのかは分からない。誰にでも通じるような説明をするには、31文字は決して十分とは言えないのだ。
現実には、フォルダの名前を大分類とし、その中の小分類としてファイル名を付けるというような工夫をするわけだが、これもやはり限界がある。きちんとした管理が可能なら、インデックスを作ってハイパーリンクにしたり、テキストデータベースを作るなどの方法を取ることになるだろう。しかし、最初にも述べたように、常に整然とした管理ができる体制にあるとは限らないし、そもそもインデックスやキーワードの付け方によっては、全く必要な情報にたどり着けないという事態も起こり得る。
ユーザーの多様なニーズに応え、増加するテキストをうまく活用するには、全ファイルにわたって全文を対象に情報を検索する仕組みが必要だ。今回の課題は、そういう訳で、ハイパーカードによる全文検索システムの作成である。
必要なファイルを見つけだす
ある程度フォルダ単位で文書がまとめられているという前提で、ここではハイパーカードで特定のフォルダを全文検索する方法を考えてみる。
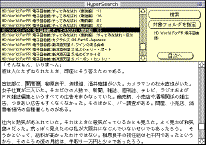 単純に検索語句がファイル内にあるかどうかをチェックするなら話は比較的簡単だ。リスト1は対象となるフォルダのパスと検索語句を受け取って、該当するファイルのリストを返す関数である。まず、2行目で外部命令AllFiles()を用いてTEXTタイプのファイルとフォルダのリストを取得(*注2)。ファイル名の最後が":"の場合はフォルダを表すので、6行目で自らを再帰的に呼び出してサブフォルダを検索していく。ファイルの場合は、いったんその中身を読み込み、offset関数(*注3)を使って検索語句の有無を調べる(9行目)。結果が0ならば語句は存在しないからこのファイルは無視すればよい。正の整数が返ってくれば語句が見つかったということ。ファイルのパス名を記録しておこう。
単純に検索語句がファイル内にあるかどうかをチェックするなら話は比較的簡単だ。リスト1は対象となるフォルダのパスと検索語句を受け取って、該当するファイルのリストを返す関数である。まず、2行目で外部命令AllFiles()を用いてTEXTタイプのファイルとフォルダのリストを取得(*注2)。ファイル名の最後が":"の場合はフォルダを表すので、6行目で自らを再帰的に呼び出してサブフォルダを検索していく。ファイルの場合は、いったんその中身を読み込み、offset関数(*注3)を使って検索語句の有無を調べる(9行目)。結果が0ならば語句は存在しないからこのファイルは無視すればよい。正の整数が返ってくれば語句が見つかったということ。ファイルのパス名を記録しておこう。
リスト1の検索が終了したら、ヒットしたファイルの一覧をフィールドに書き込み、クリックで該当するファイルを読み出して別のフィールドに表示できるようにする。このとき、検索語句をfind stringで調べてやれば、検索語句にすぐにジャンプするのでより使いやすいだろう(画面2)。
条件を追加して調べる(AND検索とOR検索)
条件を追加しての絞り込み検索も簡単である。今度は対象となるファイルが限定されている(先ほどの検索結果がそうだ)ので、そのパスを使ってリスト2のように検索していく。offset関数を使って調べるのは、リスト1の検索と同様だ。
最初から条件(キー)を複数指定してAND検索やOR検索を行うのはどうだろう。これも理屈はそれほど難しくない。AND検索なら、それぞれのファイルに対して与えられたキーを順番にチェックし、全てが見つかった場合のみファイル名を記録する。リスト1の9〜10行目をリスト3で置き換え、引数swに検索語句のアイテムリストを与えればよい。OR検索の時は、複数のキーのうち一つでも見つかれば良いのだから、今度はリスト4を用いる。これはリスト3とほとんど同じだが、1,3,4行目がそれぞれ逆の関係になっていることに注意しよう。結果の表示関連は前節のものがそのまま利用できる。
ファイルから段落を抽出する
検索するファイルのサイズがかなり大きくて、様々な内容が詰め込まれている場合、どのファイルに情報があるということを示すだけでなく、該当する情報をファイルから抽出してしまいたい。ここでは、ファイルの何段落目に情報があるというところまでを調べる方法を考えてみる。
フォルダのファイルリストを取得し、それぞれのファイルを読み込むまではリスト1と同じ。そのあとで段落情報を調べる部分はリスト5のようになる。offset関数で検索語句の位置が分かったら、それが何段落目になるのかを確認するために、6行目で先頭から見つかったところまでの段落数(linePos)を数えている。目的の言葉は複数箇所にあるかもしれないので、検索済みの段落までを削除したうえで(9行目)さらに残りのテキストを調べていく。これを検索語句が見つからなくなるまで繰り返すわけだ。
やや複雑なのは、用済みのテキストを削除しながら検索しているために、6行目で調べたlinePosが単純に段落位置にならないところである。そのため、検索対象の(つまり残りの)テキストstrがファイルの中では何段落目以降であるかを変数startLineに納めておき(2, 8行目)、これをlinePosに加えるという作業が必要になる(7行目)。
この例では単純化のためにファイルパスと段落番号のみを返すようにしたが、番号だけでなくその段落のテキストそのものを返すのも難しくはない。簡潔、かつ必要にして十分な情報をフィールドに表示して、検索結果が本当に必要な内容かどうか確認できるようにすることが大切だ。サンプルのスタックでは、ファイル名、段落番号と最初の50文字を表示し、クリックでその段落の前後数行を読むことができるようになっている(画面3)。
検索辞書(シソーラス)を用意して効率的にファイルを探す
オフィスで書類を調べるとき、明確にひとつの単語だけを目指してページを繰っていくことはあまりない。それよりも、漠然とした単語のグループを頭に浮かべ、その場に応じて無意識にOR検索を行っているのが普通だろう。このような単語のグループがあらかじめ分かっていれば、そうした一群の単語を辞書のようにして用意しておき、自動的にOR検索を行わせることが可能だ。
シソーラスとは、例えば「会長、社長、専務、常務」のようなまとまりに対して「経営トップ」という代表語句を与えた辞書と考えればよい。「経営トップ」という項目を選んで検索すると、「会長、社長、専務、常務」のいずれかを含むテキストがリストアップされるという仕掛けだ。「酒」を選べば「ウイスキー、ワイン、ビール」が検索されるというのでもいい。それぞれのオフィスに合ったシソーラスを備えておけば、効率の良い検索ができるはず。シソーラスは、組織ごとの情報探索ノウハウを蓄積したものと言ってもいいだろう。
画面4のサンプルは、ポップアップメニューで項目を選ぶと、別のフィールドに用意した辞書から検索語句のグループが取り出され、前に述べた _OR検索_ のスクリプトに引数として渡されるというものだ。この先はこれまでの検索システムと同じように、必要に応じてファイル名のリストを表示したり、段落ごとに調べたりする機能を加えていく。簡単な仕組みだが、シソーラスの出来次第では大きな威力を発揮するはずだ。
* * *
フリーウェアも含めて検索ユーティリティはいくつも存在する。一般にはこうしたツールを使う方が高速だろう。しかし、フォルダを限定した検索ならこのハイパーカードシステムも十分実用的なスピードを発揮する。さらにハイパーカードを使えば、これまでに検討したデータベースやハイパーテキストと組み合わせた独自のツールも作成可能だ。カスタマイズできるという利点を生かして、ニーズにあった強力なオフィス文書活用システムを構築してみるといいだろう。
注
*注1
漢字Talk7.5では「一般設定」の中に「書類」という項目が加わったが、もとの書類があったフォルダを使用するオプションは用意されていない。筆者の知る限りでは、これを回避する方法はナウ・ウーティリティのスーパーブーメランを使うぐらいしかない。
*注2
フォルダ内のファイルを一括検索するには、まずその中にあるファイルのリストがどうしても必要だが、ハイパーカードにはこの機能がないので、サンプルスタックには外部命令を用意した。この関数は引数としてフォルダのパス、ファイルタイプ、リストにフォルダを含むかどうかを取る。
*注3
1995/7号の用語解説で示したように、ある文字列が別の文字列の何文字目に含まれるか(もしくは含まれないか)を調べる関数。HCのver2.3では、この関数が正しく働かないことがある。対処法についてはこの説明を参照。
リスト
リスト1
--ReadFile()はファイルの中身を読み出す関数 --swは引数として与える検索語句(Search Word) 1: function findMatch thePath, sw 2: put AllFiles(thePath,"TEXT", TRUE) into FileList 3: put empty into res 4: repeat with i=1 to number of lines of FileList 5: if last char of line i of FileList is ":" then 6: put findMatch(thePath & line i of FileList, sw) after res 7: else 8: get ReadFile(thePath & line i of FileList) 9: if offset(sw, it) > 0 10: then put thePath & line i of FileList & RETURN after res 11: end if 12: end repeat 13: return res 14: end findMatch
リスト2
--PathListはフルパス名のリスト 1: function AndSearch PathList, sw 2: put empty into res 3: repeat with i=1 to number of lines of PathList 4: get ReadFile(line i of PathList) 5: if offset(sw, it) > 0 6: then put line i of PathList & RETURN after res 7: end repeat 8: return res 9: end AndSearch
リスト3
--AND検索を行う。リスト1の9〜10行目を置き換える。 1: put TRUE into status 2: repeat with k=1 to number of items of sw 3: if offset(item k of sw, it) = 0 then 4: put FALSE into status 5: exit repeat 6: end if 7: end repeat 8: if status is TRUE 9: then put thePath & line i of FileList & RETURN after res
リスト4
--OR検索を行う。リスト1の9〜10行目を置き換える。 1: put FALSE into status 2: repeat with k=1 to number of items of sw 3: if offset(item k of sw, it) > 0 then 4: put TRUE into status 5: exit repeat 6: end if 7: end repeat 8: if status is TRUE 9: then put thePath & line i of FileList & RETURN after res
リスト5
--情報のある段落まで調べる。 --リスト1の8〜10行目を置き換える。 1: put ReadFile(thePath & line i of FileList) into str 2: put 0 into startLine 3: repeat 4: get offset(sw, str) 5: if it = 0 then exit repeat 6: put number of lines of (char 1 to it of str) into linePos 7: put thePath & line i of FileList & TAB & linePos + startLine & RETURN after res 8: add linePos to startLine 9: delete line 1 to linePos of str 10: end repeat
★HC ver 2.3でのoffset関数について
HC 2.3のoffset関数は、全く関係のない語句でも一致しているとみなしてしまうことがあります。例えば
offset("純粋","システム")
という式は当然0を返すはずですが、ver 2.3で実行すると3という結果になります。つまり、ファイル中に「純粋」という語句がなくても「システム」という語句があればoffsetを使った検索ではヒットしてしまうということになるわけです。こうした文字の組み合わせは非常にたくさんあり、そのままではoffset関数は使いものになりません。
この号で作成したサンプルスタックではこの問題を回避するために、"dummy"という(フォントにOsakaなどの日本語を指定した)中身が空のフィールドを作り、ファイルから読み込んだ文字列にこのフィールドをつけ加えています。すなわち、ファイルの文字列をstrとすれば、
put fld "dummy" after str
のような操作をしています。もちろんこれによってstrの中身は変化しませんが、offset関数は、この場合は正しく動作するようになります。つまり、検索対象の文字列が日本語であるということを(空のフィールドをつけ加えることで)明示的に示してやると、offsetは正しく働くようになるのです。
ご自身でoffset関数を使った検索スクリプトを書かれる場合、HC 2.3をお使いの方はこの点にご注意下さい。
(MacUser Japan, January 1996)